0.Abstract
- skip-gram按理比cbow要准确,但是训练速度比其更慢。在本文中,我们提出了几个扩展,可以提高向量的质量和训练速度。
- 对频繁单词进行二次取样。
- 还学习了更多的常规单词表示。
- 描述了一种称为负采样的分层softmax的简单替代方案。
- 单词表示的固有局限性是它们对单词顺序的漠不关心以及它们无法表示惯用短语。我们提出了一种在文本中查找短语的简单方法。
1.Introduction
- Skipgram模型的训练不涉及密集矩阵乘法,这使得训练非常有效。
- 本文:
- 在训练期间频繁词的子采样导致显着的加速(大约2x-10x),并且提高了较不频繁词的表示的准确性。
- 我们提出了一个简化的噪声对比度估计(NCE)变体,用于训练Skip-gram模型,与更复杂的相比,可以更快地训练和更好的矢量表示。
- 单词表示受限于它们不能表示不是单个单词的组成的惯用短语。 例如,“波士顿环球报”是一份报纸,因此它不是“波士顿”和“环球报”含义的自然组合。 因此,使用向量来表示整个短语使得Skip-gram模型更具表现力。我们使用数据驱动方法识别大量短语,然后在训练期间将短语视为单独的标记。
- 发现了Skip-gram模型的另一个有趣特性:可以做向量加法。
2.skip-gram模型
-
目标:最大化对数概率
-
模型:其中vw和vw′分别为w的输入和输出向量表示,W为词表中单词数。W通常会达到10^5-10^7量级。
2.1分层softmax
- 不需要评估神经网络中的W个输出节点以获得概率分布,仅需要评估约log2(W)个节点。 是softmax的近似。
- 共有W个叶子节点,对于每个节点,显式地表示其子节点的相对概率。这些定义了一个可将概率分配给单词的random walk(随机游走)。
- 目标函数:见论文
2.2负采样
-
分层softmax的替代方案是噪声对比度估计(NCE)。NCE认为一个好的模型应该能够通过逻辑回归将数据与噪声区分开来,这类似于铰链损失(hinge loss ),通过对噪声上的数据进行排名来训练模型。
-
虽然NCE可以最大化softmax的对数概率,但是Skipgram模型只关注学习高质量的向量表示,因此只要向量表示保持其质量,我们可以随意简化NCE。
-
目标函数:
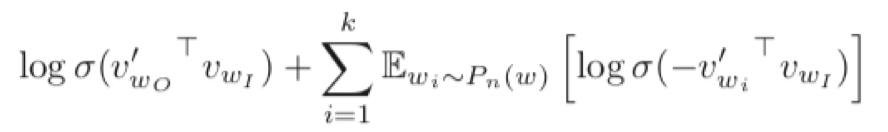
-
符号:
- Pn(w):目标词不是w的上下文的概率分布(来自噪声)
- k:对于每个数据样本存在k个负样本, 5-20范围内的k值对于小型训练数据集是有用的,而对于大型数据集,k可以小到2-5。
-
采样函数:使用“一元模型分布(unigram distribution)”来选择“negative words”。一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。公式中开3/4的根号完全是基于经验的,论文中提到这个公式的效果要比其它公式更加出色。
2.3频繁词子采样
-
频繁词提供的信息价值低于稀有词。比如:France和Paris一起出现,比France和the一起出现要提供更多的信息,因为the可能与很多词更多出现。经过很多次迭代训练之后,再次更新的时候高频词的向量不应该改变太大。
-
经过几百万个例子的训练后,频繁词的矢量表示没有显着变化。
-
为了抵消罕见和频繁单词之间的不平衡,我们使用了一种简单的子采样方法:训练集中的每个单词wi被丢弃的概率由公式计算,其中f(wi)是单词wi的频率,t是选择的阈值 ,通常在10-5左右,则训练集中每个单词wi被丢弃的概率为:
P(wi)=1-√(t/f(wi))
-
它积极地对频率大于t的单词进行子采样,同时保留频率的排名。 虽然这个子采样公式是启发式选择的,但我们发现它在实践中运作良好。 它可以加速学习,甚至可以显着提高稀有单词的学习向量的准确性。
3.实验结果
- 负抽样在类比推理任务上优于Hierarchical Softmax,并且甚至比噪声对比估计具有更好的性能。
- 频繁单词的子采样可以多次提高训练速度,使单词表示更加准确。
4.学习短语表示
-
许多短语的含义并不是其单个词的含义的简单组合。
-
可以用所有可能的n-gram来训练skip-gram模型,但是这会导致过于记忆密集。
-
我们使用单gram和双gram数目形成短语, 我们先找到经常一起出现而很少在其他语境中出现的单词。这样就可以组成许多短语并且不会大量扩充词表(短语表)。通过如下公式将训练集中的最可能组成Pharse的词汇找出来将其变成一个token(卡一个阈值来决定是不是短语,在处理的时候会2-4次处理训练集,并将score的阈值不断调小,这样可以使得模型能够将多词组成的phrase通过多次的扫描数据集不断拼接出来。),对于某些词语,经常出现在一起的,我们就判定他们是短语。那么如何衡量呢?用以下公式:
- δ——折扣系数,防止将很低频的词汇也赋予较高的score,使得其也变成一个Phrase。
-
输入两个词向量,如果算出的score大于某个阈值时,我们就认定他们是“在一起的”,为了考虑到更长的短语,我们拿2-4个词语作为训练数据,依次降低阈值。
5.Additive Compositionality
-
在模型中训练的词向量存在着如下的线性结构关系:vec(Russian)+vec(river) = vec(Volga River).这种可能可以理解成词向量其实是包含了它的分布特性在向量表示中,因为词向量就是通过用目标词的词向量预测它的上下文中的词来训练词向量的。所以它会在向量中包含它的上下文信息。Volga River很频繁的与Russian以及River出现在相同的语境中。而向量加法操作可以看成是两个词语的上下文分布的并操作,因为只有两个向量都很大的维度,才会在结果向量中比较突出,代表这个语义更明显。所以在Russian与river的并操作上下文中,Volga River的上下文也与其类似,所以它们的词向量也很接近。
-
词向量与softmax非线性的输入成线性关系。当训练单词向量以预测句子中的周围单词时,可以将向量看作表示单词出现的上下文的分布。这些值与输出层计算的概率呈对数关系,因此两个字向量的总和与两个上下文分布的乘积有关,乘积可以看作AND函数(词的组合)。
参考文献
- http://qiancy.com/2016/08/24/word2vec-negative-sampling/
- https://zhuanlan.zhihu.com/p/39684349
- https://www.cnblogs.com/pinard/p/7249903.html
-
https://blog.csdn.net/imsuhxz/article/details/82115681
- https://blog.csdn.net/huhu0769/article/details/81194565