1.Introduction
-
User response prediction问题:离散、categorical、multi-field
- 基于onehot编码的线性模型:易实现、训练高效、性能差(不能捕捉非独立特征之间的交互)
- LR
- 朴素贝叶斯
- FTRL
- 非深度学习非线性模型:性能好、不能充分使用所有不同的特征组合、泛化能力受到限制(浅层模型、复杂数据表达能力有限)。
- FM:将item和user的特征映射到低维连续空间。
- 梯度提升树
- 深度学习非线性模型(DNN):探索局部相关性,建立特征空间的密集表示,使神经网络模型能够有效地直接学习高阶特征原始特征输入。
3.DNNs for CTR Estimation given Categorical Features
3.1FNN
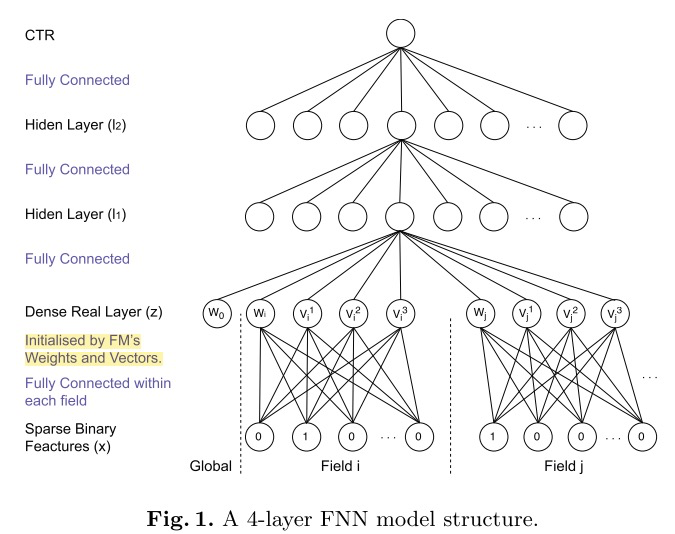
- 上图中假设隐向量的长度为3,注意有个wi和w0要加进去。
- 两阶段训练:
- input层:
- 训练FM模型,将FM的embedding向量作为FNN底层参数的初始值。(即:加入了先验知识,防止因为数据稀疏带来的歧义造成模型参数偏差,网络中没用FM强行交叉)。
- 训练时FM表达也会被训练到,具体权重更新方式见论文。
- if the observational discriminatory information is highly ambiguous (which is true in our case for ad click behaviour), the posterior weights (from DNN) will not deviate dramatically from the prior (FM)。
- DenseRealLayer 将FM产出的低维稠密特征向量进行简单拼接,作为全连接层的输入。
- 全连接层:
- 采用 tanh 激活函数(实验得出,可能是因为tanh收敛更快),最终使用 sigmoid 将输出压缩至0~1之间作为预测。
- 隐藏层使用对比散度的RBM预训练来初始化,有效地保留了输入训练数据集中的信息。
- input层:
3.2SNN
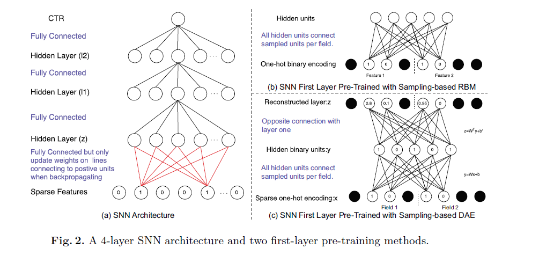
- input层:
- 是全连接层,不区分不同field,用sigmoid函数激活。
- 用对比散度的RBM和DAE来预训练。
- 提出sample-based RBM(SNN-RBM)、sampling-based DAE(SNN-DAE)来降低pre-training时的计算复杂度。
3.3正则化
4.实验
4.1Setup
- 数据:iPinYou数据集,19.5M(14.79K正样本),所有特征都是离散值(937.67K离散值)。
- 模型:Theano实现。
- LR:
- FM
- FNN
- SNN
- Metric:AUC
4.2实验表现
- FM不一定比LR好:2阶特征交互不够好,不能捕捉数据中的pattern。
- FNN和SNN最好。
- SNN-DAE和SNN-RBM性能基本一致。
4.3超参数调节
- sgd来优化
- early stopping
- lr:1、0.1、0.01、0.001、0.0001中选
- negative unit sample率:尝试每个field1、2、4。
-
激活函数:线性、sigmoid、tanh
- 固定每层神经元个数,尝试3、4、5层:3层隐藏层效果最佳。
- 每层参数相同,调整神经元个数:比钻石型网络结构好,菱形网络比每层参数相同的网络好(可能这种特殊形状网络对网络能力有一定限制,在测试集上有更好的泛化)。
4.5正则化
- L2
- dropout:效果更好。SNN对droupout敏感,FNN不是很敏感(可能因为SNN底层是全连接,FNN底层是部分连接,只连接激活部分)。
5.结论
-
FM中进行特征组合,使用的是隐向量点积。将FM得到的隐向量移植到DNN中接入全连接层,全连接本质是将输入向量的所有元素进行加权求和,且不会对特征Field进行区分,也就是说FNN中高阶特征组合使用的是全部隐向量元素相加的方式。说到底,在理解特征组合的层面上FNN与FM是存在Gap的,而这一点也正是PNN对其进行改进的动力。
-
在神经网络的调参过程中,参数学习率是很重要的。况且FNN中底层参数是通过FM预训练而来,如果在进行反向传播更新参数的时候学习率过大,很容易将FM得到的信息抹去。个人理解,FNN至少应该采用Layer-wise learning rate,底层的学习率小一点,上层可以稍微大一点,在保留FM的二阶交叉信息的同时,在DNN上层进行更高阶的组合。