Abstract
- 关于用户行为数据有两个关键观察:
- 多样性。用户在访问电子商务网站时对不同种类的商品都感兴趣。
- 本地激活(local activation)。用户是否单击点击商品只取决于其相关历史行为的一部分。
- DIN:
- 通过兴趣分布(interest distribution)来表示用户各种兴趣,设计了一个类似于attention的网络结构来根据召回广告激活相关兴趣(activate the related interests according to the candidate ad)。
- 大规模稀疏网络训练忠容易遇到过拟合问题,提出了一种自适应正则化技术。
1.Introduction
- 目前CTR模型:自动学习特征之间的非线性关系。但是这些MLP模型往往缺乏深刻理解和利用行为数据的特定结构,从而留有进一步改进的空间。
- 在输入上使用嵌入层
- 然后添加完全连接的层
- 电商数据性质:
- 兴趣多样性:用户在访问电子商务网站时对不同种类的商品感兴趣。 例如,年轻的母亲可能同时对T-shits,皮革手提包,鞋子,耳环,儿童外套等感兴趣。
- 本地激活:由于用户兴趣的多样性,只有部分用户的历史行为会影响每次点击。 例如,游泳者将点击推荐的护目镜,主要是因为购买了游泳衣,而不是上周购物清单中的书籍。
- 机器翻译中的注意力机制:
- 与候选广告具有较高相关性的行为获得较高的关注分数并且主导预测。
- 实验表明:GAUC(组加权AUC)指标下DIN优于DNN。
- 在大规模稀疏输入的这种工业深度网络的训练中容易遇到过度拟合问题。
- 提出了一种有用的自适应正则化技术:该技术被证明对于改善我们应用中的网络收敛是有效的。
- DIN在X-Deep Learning平台上运行,该平台支持模型并行和数据并行,自动化参数优化。
- 本文贡献:
- 我们研究和总结了工业发展应用中互联网规模用户行为数据的两个关键结构:多样性和本地激活。
- 我们提出了DIN,它可以更好地捕捉行为数据的特定结构,并改善模型性能。
- 我们引入了一种有用的自适应正则化技术来克服训练具有大规模稀疏输入的工业深度网络中的过拟合问题,这可以推广到类似的工业任务。
- 我们开发XDL,一种用于深度网络的多GPU分布式培训平台,可扩展且灵活,以支持我们的高性能多样化实验。
2.相关工作
- NNLM解决维度诅咒,是embedding的开山鼻祖。
- LS-PLM和FM:可以看作是一类具有一个隐藏层的网络,它首先在稀疏输入上使用嵌入层,然后对输出施加特殊设计的变换函数,旨在捕获它们之间特征的组合关系。
- Deep Crossing、Wide&Deep Learning、the YouTube Recommendation CTR model:通过用复杂的MLP网络取代变换函数来扩展LS-PLM和FM,在很大程度上取代了手动人工特征组合。这些模型通常在嵌入图层后添加池化层,使用sum或average等操作来获得固定大小的嵌入向量。这将导致信息丢失,无法充分利用用户丰富行为数据的内部结构(inner structure)。
- attention:
- NMT采用所有译文的加权和来获得预期译文,并且仅关注与双向RNN机器翻译任务中的下一个目标词的生成相关的信息。
- DeepIntent采用attention技术来建模数据丰富的内部结构(rich inner structure of data),给不同单词不同的注意力分数,从而获得更好的句子表示。然而在query和文档中没有交互,也就是说query和文档表示是固定的,这违反了电商数据的“本地激活”特性。这种情况与我们不同,因为在DIN模型中,用户表示在显示广告系统中随着不同的候选广告而自适应地改变。
3.系统概述
-
业务场景:召回、rank、点击、记录log,闭环。
-
数据特征:见Introduction。
-
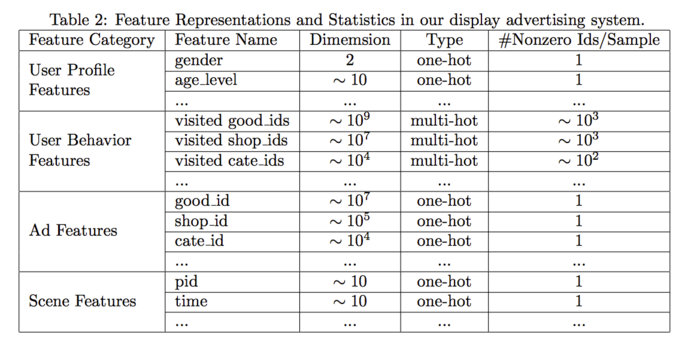
特征表示:稀疏ID,分为四组(用户特征、用户行为特征、广告特征、上下文特征)。如下:
-
GAUC:是AUC的推广,GAUC是每个用户样本计算的AUC加权平均值。 权重可以是展示次数或点击次数。因此,该方法可以消除用户偏差的影响(有些用户天生就是点击率高),并更准确地测量模型对所有用户的性能。 经过多年在我们的生产系统中的应用,GAUC指标被证实比AUC更稳定和可靠。如下:
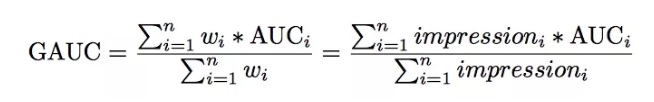
4.模型结构
- 与搜索不同,大多数用户进入展示广告系统之前没想好自己要什么。
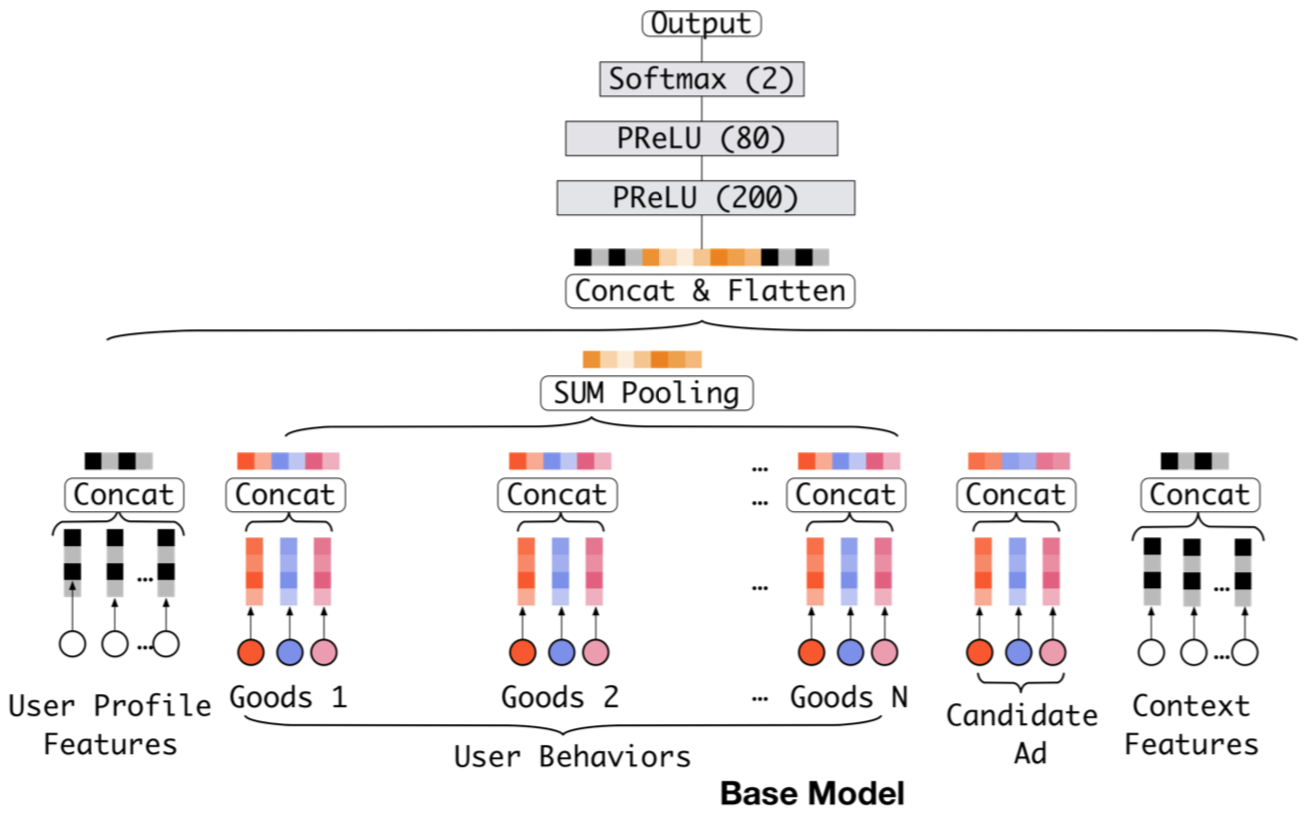
4.1Base Model
-
结构:
- embedding+dnn
- 由于输入包含用户行为ID,其长度不定,因此在embedding和dnn之间添加pooling层(sum pooling or average pooling)。
4.2DIN
-
motivation:base model有很大局限
- 深入到池化操作中,我们会发现很多信息都丢失了,也就是它破坏用户行为数据的内部结构。k维向量最多表达k个独立兴趣,但是实际独立兴趣有很多。
- 用户历史点击行为来自于用户的部分兴趣。不管候选的广告是什么,这个pooling操作得到的向量对一个固定的用户来讲都是相同的,这是很武断的。
-
解决方案1:
- NMT假设在decoder阶段一个句子中的词语重要程度不同。Attention网络可以被视为特殊的pooling层,学习给每个词语不同的权重,遵循了数据的多样结构(diversity structure)。
- 在当前AD场景下直接使用Attention层是不合适的,用户兴趣的embedding向量应该根据不同的候选广告而变化,即:应该遵循本地激活特性。
-
解决方案2:
- 假设用内积来表示user embedding向量和ad embedding向量的相关性,F(U, A) = Vu • Va。如果用户U和广告A、用户U和广告B都很相关,则AB连线的之间的任何点都和U有很高相关性得分。
- 它为用户和广告的分布式表示向量的学习带来了严格的约束。 可以增加向量空间的嵌入维数以满足约束,这可能有效,但会导致模型参数的大量增加,overfit的可能性。
-
解决方案3——DIN
- 思想:
- 分布角度:用户兴趣不再用一个点表示,转而用一个分布,分布可以是任意多峰的,可表达任意多独立兴趣,峰值的大小表示兴趣强度。那么针对不同的候选广告,用户的兴趣强度是不同的,也就是说随着候选广告的变化,用户的兴趣强度不断在变化。
- attention角度:用户历史行为embedding向量变为了召回广告A的函数,对embedding进行求和变为对embedding进行加权求和。
- 公式:
- Vi:第i个行为的embedding向量(比如商品id、shop id等)
- Va:候选广告的嵌入向量
- Vu:所有行为ID的加权和,表示用户总体兴趣强度,表现出的兴趣向量随兴趣点不同而变。
- wi:attention得分,是行为id i相对于候选广告A的贡献关注度得分。在实现中,wi是Vi、Va为输入的激活函数的输出。
-
结构:
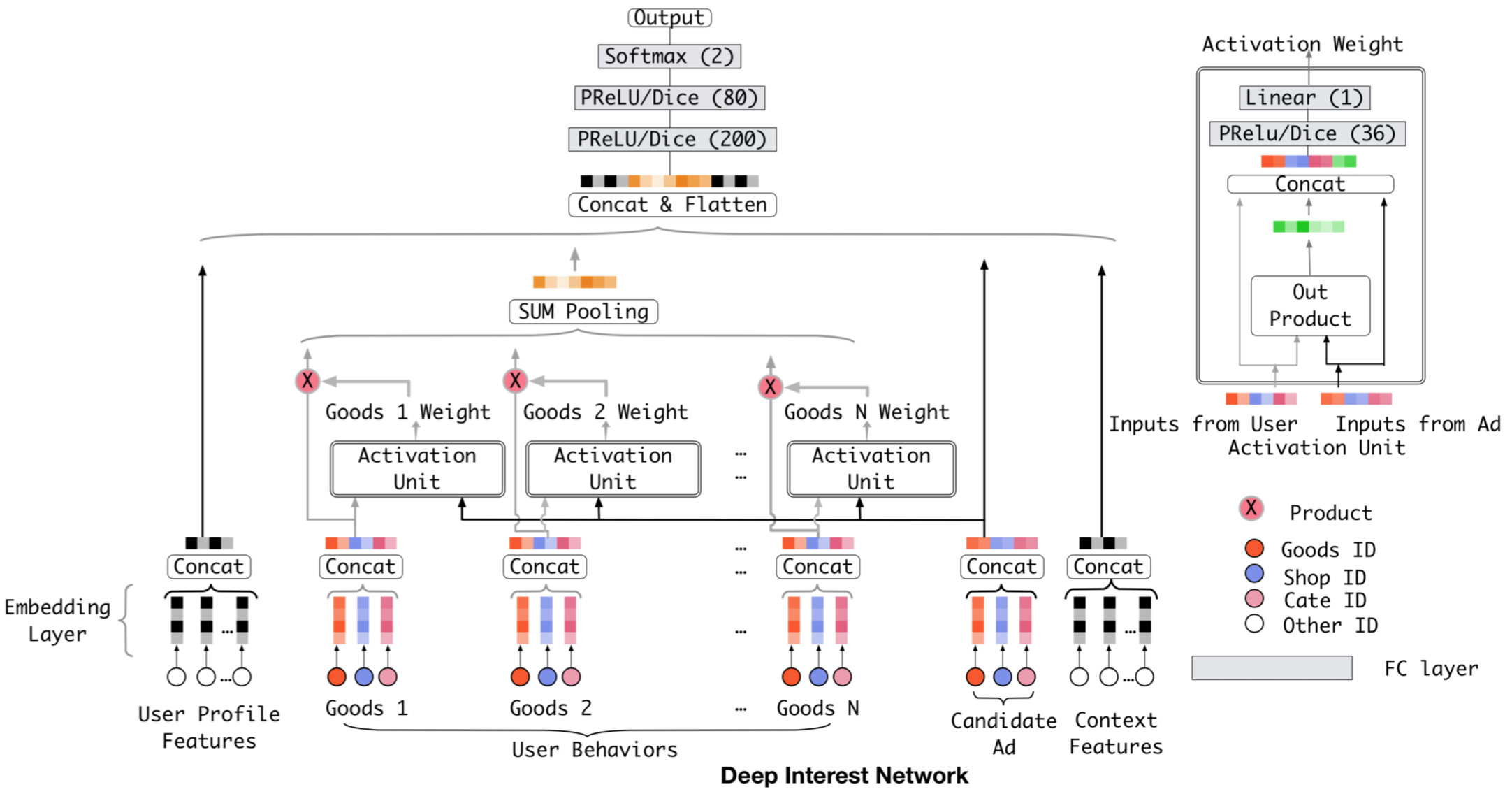
- 思想:
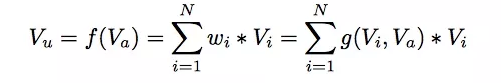
4.3数据相关的激活函数
-
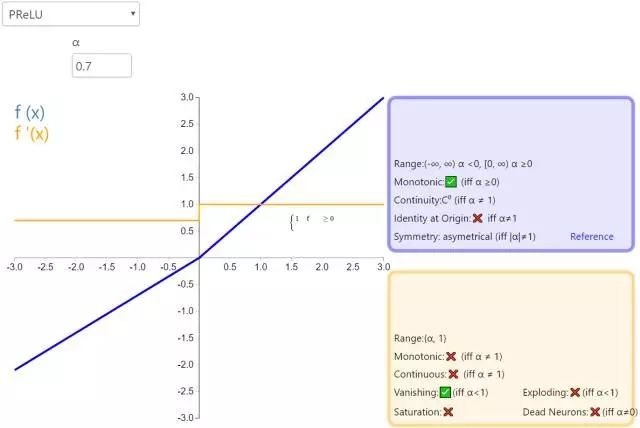
PReLU:base模型一开始用PReLU。
- 性质:
- 当ai很小的时候,PReLU和Leaky ReLU一样,退化为Leaky ReLU。
- 当ai为0时,退化为ReLU。
- 作用:防止梯度消失。PReLU可以提高精度,但会有额外的过拟合风险。
- 公式:

- 图示:
- 性质:
-
Dice:
- motivation:为了进一步提高模型的收敛速度和性能,我们考虑并设计了一种新的数据相关激活函数。用渐变的函数做补足,补足的方式和数据分布有关。根据minibatch的期望方差自适应调整校正点,而Relu采用硬校正点0。
- 公式:
-
其中pi的计算步骤:
- 对进行正态分布标准化(z-score)处理,使得数据集中在正态分布均值处;
- 利用sigmoid函数归一化,使得输出在0~1之间。
-
ai是超参数,推荐值为0.99。
-
可以理解Dice为是一种平滑操作。
-
其中E和Var计算如下:
- training中直接统计每个batch数据即可。
- test:采用动量来预估期望和方差:
-
Dice的关键思想是根据数据自适应地调整整流点,这与使用基于yi> 0的硬整流器的PReLU不同。这样,Dice可以被视为具有两个通道的软整流器:基于pi的aiyi和基于pi的yi 。 pi是保持原始yi的权重,当yi偏离当前batch的E [yi],它将是较低的。
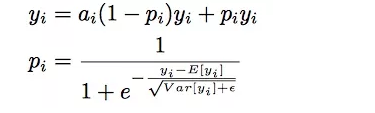
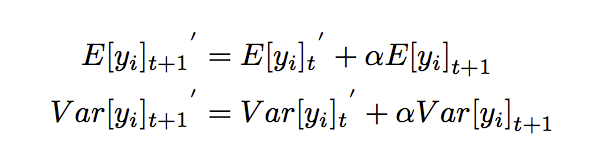
4.4自适应正则方法
-
原因:
- 实验表明:加上细粒度的(fine-grained)用户访问商品特征,模型表现在第一个epoch后迅速下降。
- 0值特征特别多,加入正则计算的话,计算量太大。
- 众所周知,互联网的用户行为数据遵循长尾法则,也就是说,许多特征ID在训练样本中很少发生多次。 这不可避免地将噪声引入训练过程并加剧过度拟合。发现正则和频次有关,频次越高,正则压制越少。
-
解决:
-
过滤掉低频feature id(low-frequency feature ids),可以被视为手动正则。=>就信息丢失不好评估,阈值设置粗糙,这种基于频率的滤波器非常粗糙
-
自适应的正则方法:根据出现频率对特征id施加不同的正则化强度,惩罚低频特征并放松高频特征以控制梯度更新方差。通过应用商品频率的常规倒数来软化低频良好id。
- 公式:
- 其中:nj是特征i的出现频率。
-
5.实现
- 在名为X-Deep Learning(XDL)的多GPU分布式培训平台上实现,该平台支持模型并行和数据并行,组成:
- 分布式嵌入层:embedding操作参数多,分布式处理。
- 本地后端:dnn参数少,可以单机处理。重写了开源的深度学习框架tensorflow,mxnet,theano等。通过统一的数据交换接口和抽象,我们可以轻松地集成和切换到不同类型的框架中。
- 通信组件:MPI实现。
- 获得了十倍以上加速,高效自动优化参数。
6.实验
6.1DIN可视化
-
实验数据:随机选9个类别的商品和每个类别100个商品。下图是聚类效果,说明DIN的聚类特征不错,同时图中不同的商品点击率不同,用不同颜色表示,所有商品候选都是是画像为”年轻的母亲”的召回结果:
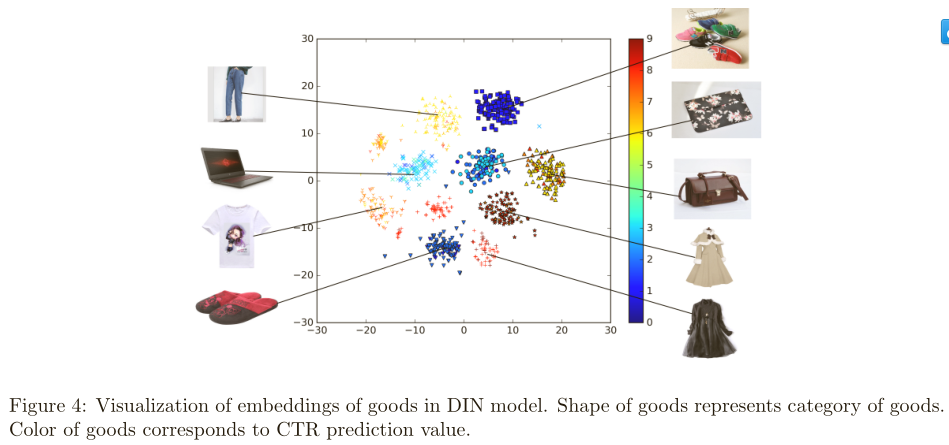
-
下图展示了激活强度(注意力分数w),正如所料,与候选广告高度相关的行为获得了高度关注:
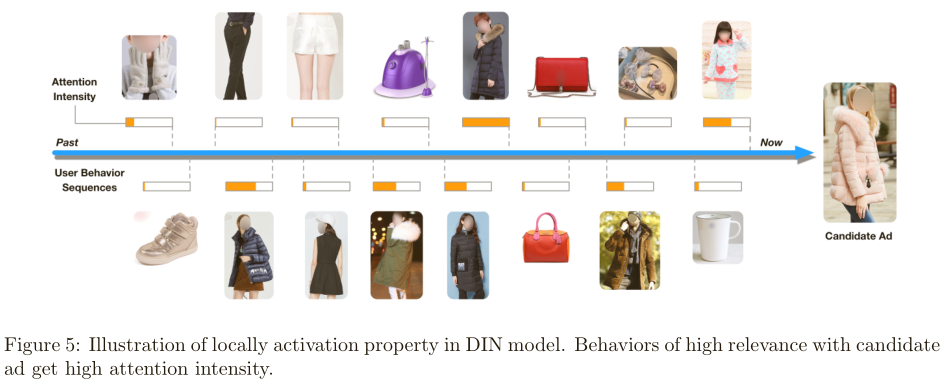
6.2正则
- 实验设计:
- Dropout:随机丢弃每个样本的50%商品id
- filter:按样本中出现频率过滤商品id,留下最常见的商品id。(2000w)
- L2正则:搜索参数λ并将其设置为0.01。
- DiFacto正则:参数λ并将其设置为0.01。
- 自适应正则:用Adam优化,搜索参数λ并将其设置为0.01。
- 实验结果:
- 自适应正则方法GAUC上涨0.7%,第一个epoch后几乎看不到过拟合,第二个epoch完成后验证集上看出几乎收敛。
- dropout方法在第一个epoch收敛慢,在第一个epoch完成后过拟合在某种程度得到缓解。
- filter在第一个epoch中保持与不加filter相同的收敛速度,在第一个epoch后,过拟合也得到了缓解,但比dropout更糟糕。