0.Abstract
- 现有的方法对低阶或高阶的交互有很强的偏向,有的方法需要专业特征工程。本文中我们提出兼顾低阶和高阶特征的端到端学习模型。
- 与Google最新的Wide&Deep模型相比,DeepFM对其“宽”和“深”部分有共享输入,除了原始特征外不需要特征工程。
- 证明DeepFM相对于基准数据和商业数据的CTR预测的现有模型的有效性和效率。
1.Introduction
- 有的系统目标是最大化点击次数(按预估ctr排序即可)、有的系统目标是提高收入(按ctr*出价排序)。
- 通常,用户点击行为背后的特征交互是高度复杂且重要的,其中低阶和高阶特征交互应该发挥重要作用。根据Google的Wide&Deep模型[Cheng et al,2016],考虑到低阶和高阶特征交互同时带来了额外的改进,而不是单独考虑二者其一。
- 已有思路:
- FTRL:广义线性模型在实践中表现不错,但是缺乏学习特征交互能力。
- 基于CNN的模型:偏向于相邻特征之间的相互作用
- 基于RNN的模型:更适合具有顺序依赖的点击数据。
- FM:原则上FM可以模拟高阶特征交互,但实际上通常由于高复杂性而仅考虑2阶特征交互。
- FNN:基于FM的NN,在应用DNN前先训练FM,因此受到FM容量(capability)限制。
- PNN:通过在embedding层和全连接层之间引入乘积(product)层。PNN和FNN与其他深度模型一样,捕获很少的低阶相互作用特征,但低阶相互作用特征对于CTR预测也是必不可少的。
- Wide&Deep:在该模型中,“宽部分”和“深部分”需要两个不同的输入,“宽部分”的输入仍然依赖于专业特征工程。来解决低阶交互不足的问题。
- DeepFM:
- 集成了FM和DNN,模拟了FM等低阶特征交互和DNN等高阶特征交互。
- 可以在没有任何特征工程的情况下进行端到端训练。
- wide部分和deep部分共享相同的输入和embedding。
2.Our Approach
2.1符号定义
- n:样本数
- m:field数(连续值分桶与否都可以)
- χ :输入
- y∈{0,1}:输出
- xfieldj:第j个field的变量
2.2模型
-
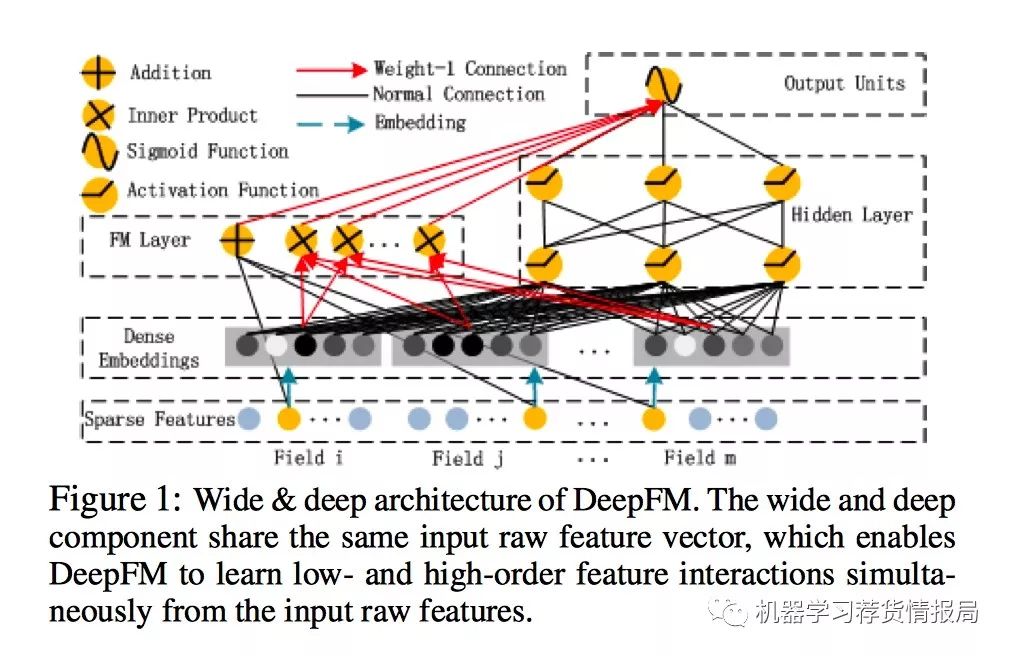
由两个组件构成:FM组件、deep组件。共享相同的输入,所有的参数在一起联合训练。
-
对于特征i:wi用于衡量其1阶重要性,潜在矢量vi用于衡量特征i与其他特征相互作用的影响。Vi以FM组件的形式输入以模拟order-2特征交互,并以deep组件的形式输入以模拟高阶特征交互。
- FM组件和DEEP组件共享相同的embedding特征,这有两点好处:
- 同时学习低阶、高阶特征交互
- 不需要专门的特征工程
-
所有参数,包括wi、vi等,都是针对组合预测模型联合训练的。
-
每个field的长度虽然可能不同,但是每个field都学习一个相同长度的embedding向量。
-
公式:y=sigmoid(yFM+yDNN)
-
图示:
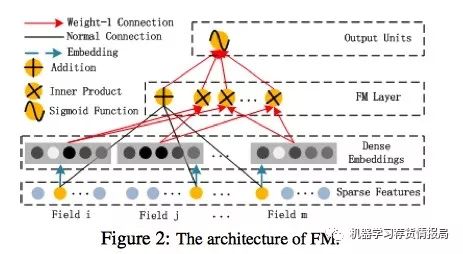
2.2.1FM组件
-
学习低阶特征交互
-
就是个FM模型
-
图示:
2.2.2Deep组件
- 学习高阶特征交互
- 与图像、音频等数据作为输入的连续密集神经网络相比,CTR预测的输入完全不同,需要设计新网络架构。
- 输入特点:高度稀疏、超高维度、分类-连续特征混合、根据field分组。所以要有个embedding层将数据转换为:低维、密集、实值向量,否则网络难以训练。
- embedding层:
- 输入feild向量长度不同,embedding层参数却都有相同的尺寸k。
- FM的隐向量V现在作为权重用,被学习并用于将输入field压缩到embedding。
- 我们不再需要通过FM进行预训练,而是以端到端的方式联合训练整个网络。
- 输出尺寸为m,输出为:a(0)=[e1,…,em]。ei是第i个field的embedding,m是field数,把不同field的embedding给concat起来。
- 图示:

2.2与其他CTR NN关系
- FNN:
- 简介:FM初始化的前馈神经网络
- 局限:
- embedding参数可能受到FM的过度影响
- 预训练阶段的开销降低了效率
- 仅能捕获高阶特征交互
- PNN:
- 简介:embedding层和第一个隐藏层之间加product层。
- 变体:IPNN(基于向量内积)、OPNN(基于外积)、PNN(基于内外积)。
- 局限:仅能捕获高阶特征交互。
- 改进:近似计算(消除一些神经元来近似计算内积)。但是发现这样的话外积不如内积可靠,因为外积近似计算会丢失大量信息,导致结果不稳定。虽然内积更可靠,但是它具有高度计算复杂度,因为product层的输出仅连接到最终输出层(一个神经元)。
- Wide&Deep:
- 简介:同时模拟高阶、低阶特征交互
- 局限:wide部分需要特征工程
- 拓展:用FM替换LR,这样就类似DeepFM,但DeepFM共享FM和Deep组件之间的嵌入特征,建模更精准。
3.实验
3.1实验设置
- 数据集:
- Criteo数据集:4500w用户点击记录,13个连续特征和26个分类特征。将数据集氛围:90%训练集、10%验证集
- 工业界数据集:app store游戏中心收集了连续7天的用户点击记录进行训练,剩下一天进行测试。整个数据集10亿记录。有app特征、用户特征、上下文特征。
- 评估指标
- AUC
- logloss
- 模型对比:
- lr
- fm
- fnn
- pnn
- wide&deep:为了消除特征工程的影响,将FM替换wide。
- deepfm
- 参数设置:
- dropout:0.5
- 网络结构:400-400-400
- 优化器:神经网络用Adam,LR用FTRL,FM用Adam
- 激活函数:tanh用于IPNN、relu用于其他模型
- 隐向量维度:10
3.2实验表现
- 效率比较:
- 用深度网络ctr模型的训练时间/lr的训练时间来代表效率。
- FNN的预训练使其效率降低
- IPNN和PNN速度比其他模型高,但仍然是计算昂贵的(由于内积的效率低)
- deepfm在所有测试中几乎都达到了最高效率
- 性能比较
- 学习特征交互提高了CTR模型预测的性能,这一观察来自于LR(这是唯一不考虑特征交互的模型)。
- 同时学习高阶、低阶交互,改善模型性能。
- 优于仅学习低阶交互的FM
- 优于仅学习高阶交互的FNN、IPNN、OPNN、PNN
- 同时为高阶(DNN)和低阶(FM)特征交互学习共享相同的特征嵌入,提高了CTR预测模型的性能。优于LR、DNN、FM等。
- AUC的微小改进可能会导致在线CTR显著增加。
3.3超参数学习
- 激活函数:relu和tanh比sigmoid更适合dnn模型。除了ipnn之外,所有的深度模型,relu都比tanh更好。这可能是relu引起稀疏性。
- dropout:设置为1.0、0.9、0.8、0.7、0.6、0.5,发现当正确设置时,所有模型都能够达到自己的最佳性能(从0.6到0.9)。
- 每层神经元数量:当神经元从400增加到800时,deepfm会稳定运行,但是opnn表现会差。每层200-400是不错的选择。
- 隐藏层数:层数增加开始会提升性能,后来会降低性能。(过拟合)
- 网络形状:测试了四种不同网络形状:恒定、增加、减少、菱形。恒定最好。
4.相关工作
- 略
5.结论
- 优点:
- 不需要pretrain
- 能学习到高阶、低阶交叉
- 提出了一种特征embedding共享策略来避免特征工程。