Abstract
- 具有非线性变换的广义线性模型被广泛用于具有稀疏特性输入的大规模回归和分类问题,通过一系列特征的交叉乘积来记忆特征交互是有效且可解释的。
- nn可以通过针对稀疏特征学习的低维密集嵌入更好地推广到看不见的特征组合。然而,当用户项目交互稀疏且高级交互时,具有嵌入的深度神经网络可以过拟合并推荐不太相关的项目。
- 本文提出wide&deep模型来联合训练宽线性模型和dnn,从而结合泛化性和记忆性。在Google Play上评估了该系统,实验表明:与仅deep或仅wide相比,该模型表现更好。
1.Introduction
-
推荐系统可以被视为检索+排名:输入是一组用户和上下文信息,并且输出是item的排序列表。给定查询,推荐任务是在数据库中查找相关项目,然后基于某些目标(例如点击或购买)对item进行排名。
-
推荐系统中的一个挑战是实现记忆和泛化。
- 记忆可以大致定义为学习item或特征的频繁共现并利用历史数据中可用的相关性。=>更热门,与用户的历史行为item更相关
- 泛化是基于相关的传递性(transitivity of correlation),并探索过去从未或很少发生的新特征组合。=>更多样。
-
现有工作有两种:
- 基于embedding的模型:如FM或DNN。
- 可以通过学习低维稠密embedding向量泛化出未见的query-item特征对。
- 当query-item矩阵稀疏且高秩(high-rank)时,例如具有特定偏好的用户或有特定方面吸引力的item。这种情况下大多数query、item不应该存在交互,但是embedding将导致对所有item的非0预测。
- 广义线性模型:如逻辑回归
- 简单、可拓展、可解释,使用onehot可以有效实现记忆,可以手动添加特征增加泛化。
- 需要手动特征工程,不会泛化到未出现在训练数据中的。
- 基于embedding的模型:如FM或DNN。
-
本文通过联合训练线性模型组件 和神经网络组件,在一个模型中实现记忆和泛化。该模型显著提高了ctr,同时满足了训练的速度要求。
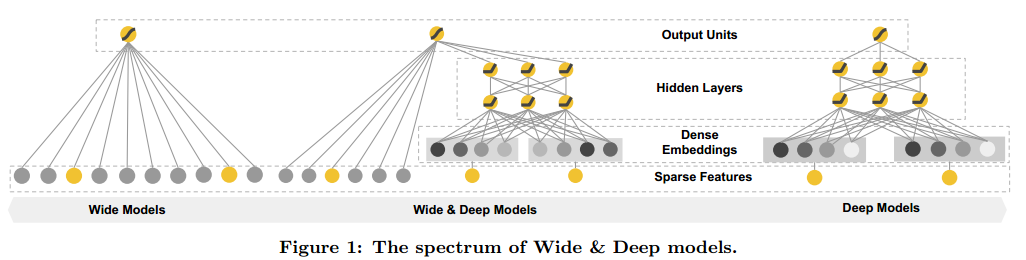
2.推荐系统概述
- 在本文中,我们将重点放在使用Wide&Deep学习框架的rerank模型上。
3.Wide&Deep
3.1Wide
- 是广义线性模型y=wTx+b,一个最重要的变换特征是cross-product transformation。这捕捉了二元特征之间的相互作用,并为广义线性模型增加了非线性。定义为(cki∈{0,1}是一个布尔变量,如果第i个特征是第k个transformatio即φk 的一部分,则值为1):
3.2Deep
- 前馈神经网络,稀疏的高维特征先转换为低维稠密实值向量(embedding),然后训练最小化损失函数。
3.3联合训练
-
wide和deep的输出加权作为结果,将其送到一个损失函数来联合训练。
-
联合训练(joint training)和集成学习(ensemble)之间有区别:
- 在集成学习中模型之间独立训练,仅在推理时合到一起。独立模型一般比较大。
- 联合训练在训练时考虑其deep和wide,用其总和来同时优化所有参数。wide部分通过补充少量cross-product transformations特征来弥补模型的deep缺点,而不是全尺寸的wide模型。
-
mini batch梯度下降反向传播,实验中wide使用了L1,deep使用了AdaGrad。
4.系统实现
4.1数据规范化
- 略
4.2模型训练
- 略
4.3模型预测
- 略
6.相关工作
- FM:通过将两个变量之间的相互作用分解为其之间低维嵌入向量的点乘来增加线性模型的泛化。
- 有人已经提出联合训练RNN和n-gram特征的最大熵模型,以通过学习输入和输出之间的直接权重来显着降低RNN复杂度
- Resnet跳层
- 深度学习与协同过滤CF结合,探索了协同深度学习。
7.结论
问题
- 为什么通过一系列特征的交叉乘积来记忆特征交互是有效且可解释的?